Pipelines
Pipelines allow you to run LLM data transforms on your data in real-time via API. Pipelines can be integrated to existing infrastructure and manually triggered via an API request to run at any time. Pipelines are recommended for DAG pipelines where there are dependencies between transforms. You can either retrieve results through polling or set up a destination such as a webhook, in warehouse within an existing database or an Omni hosted database.Define your request parameters
Define the request parameters that will be sent in the request body. These parameters will be used in the context of the transforms. The parameters defined in the UI must exactly match those passed into the body of the API request. Any inconsistencies will cause an error.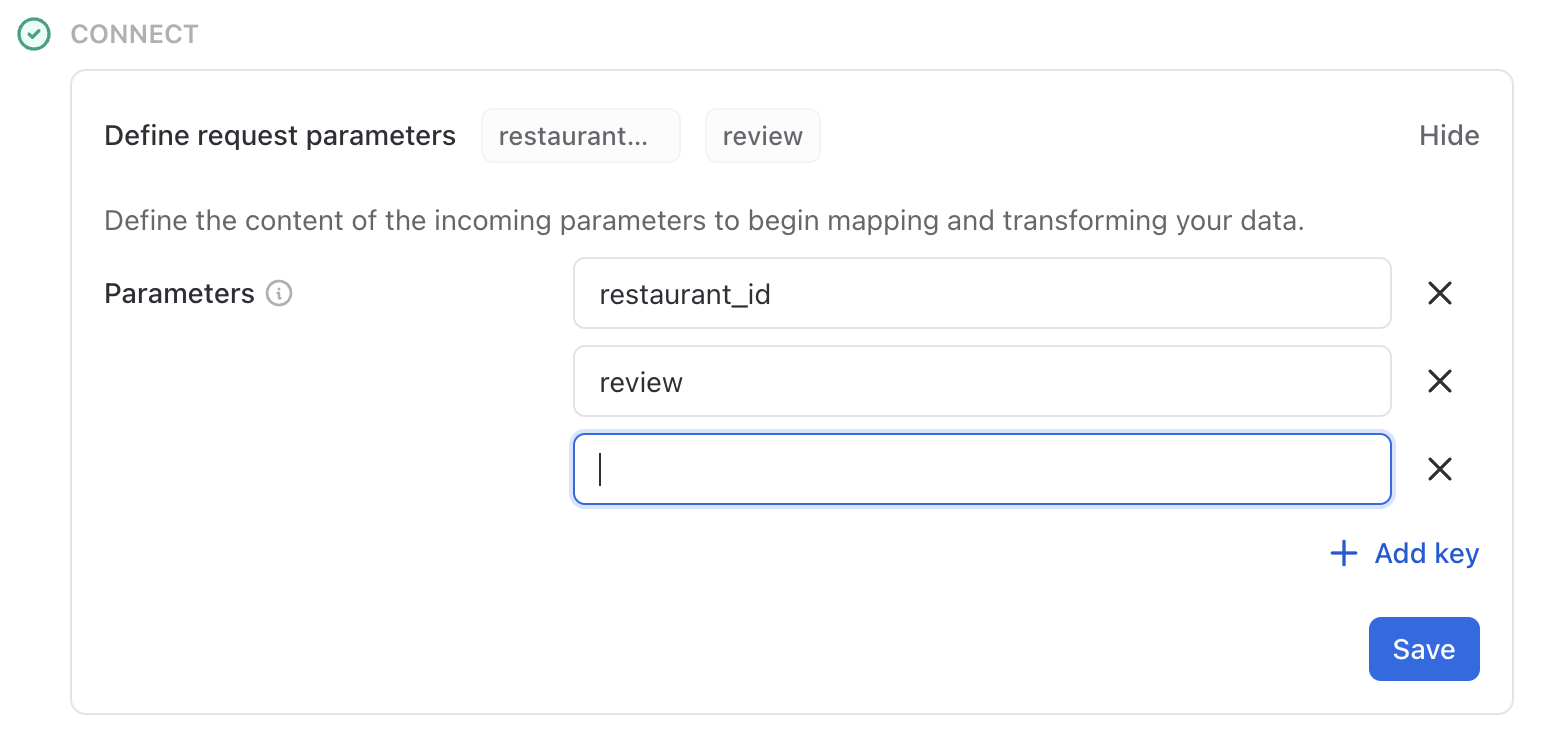
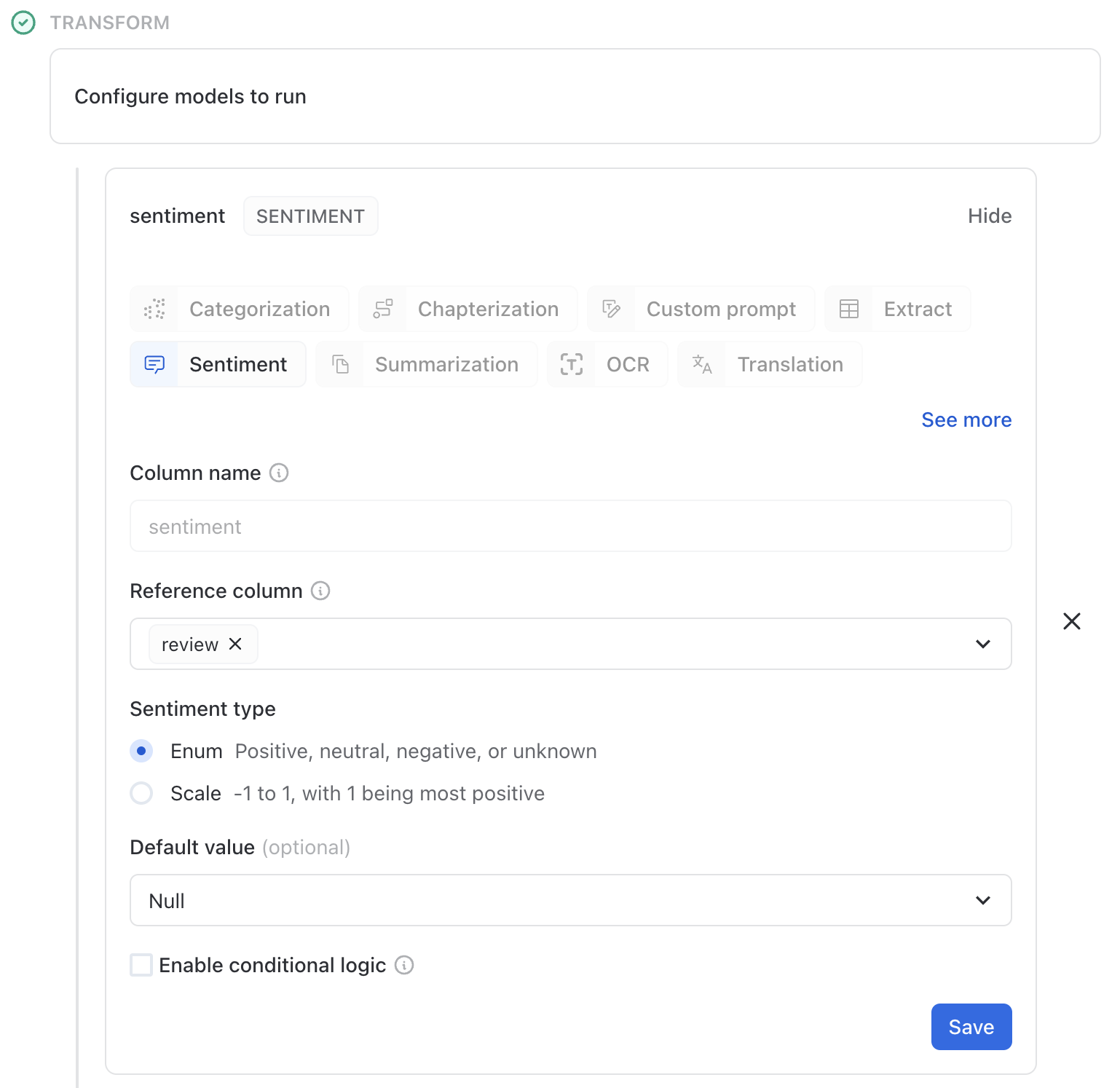
Transform your data
After defining your request parameters, the next step is to add transforms. You can choose from various models. The available models are:CATEGORIZE, CHAPTERIZE, CUSTOM_PROMPT, EXTRACT, SENTIMENT, SUMMARIZE, and TRANSLATE.